




使用JQuery模拟用户操作的方式爬取网页内容(QQ群管理)
前两天在网上看见一篇用VB爬取QQ群管理页面上QQ群员信息的一篇文章,文章是从QQ群管理网站的页面结构、接口结构入手,编写了一个基于VB语言的爬虫程序。当时作者写的那个程序只能爬出QQ号的列表,而且还是个结构及其混乱的纯文本格式,我就在想,难道爬取这些数据只能从接口入手,把每个接口的每个参数都搞清楚才能得到想要的数据吗?当然不是。
jQuery作为一个优秀的前端库,具备一系列操作DOM对象良好的接口,通过这些接口可以方便地在浏览器的DOM树中摘取自己想要的内容。于是一种从前端DOM树中挖掘自己想要的数据的思路就产生了。
首先,要解决的是目标网站是否有引入jQuery。目前jQuery的市场占有率已经相当的大,几乎随便找个带局部数据刷新的网站就有用到jQuery,所以一般情况下我们是不需要发愁jQuery的来源的,哪怕真的碰见个ajax不是用jQuery写的,我们也可以自己为当前页面引入。常上AcFun的朋友应该听说过一款叫AcFix的黑科技,它通过在A站的页面上注入一个js脚本,而这个js脚本的执行结果就是给页面上的播放器替换一个可用的视频源,同时添加一个针对AcFix的讨论框以及一系列的下载等功能按钮。我们要用相同的方式在目标页面上注入jQuery。
javascript:(function(){
var f=document.createElement('script');
f.src='https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js';
document.body.appendChild(f);
})();
压缩后就是
//将这段代码保存为chrome/firefox中的一个书签,在需要注入的页面上点击这个标签即可注入jQuery库
javascript:(function(){var f=document.createElement('script');f.src='https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js';document.body.appendChild(f);})();
于是这样我们就可以在QQ群管理的页面上不论他有没有给提供jQuery都可以保证我们有jQuery的库用。我们先打开QQ群管理页面的审查元素面板分析一下页面的结构
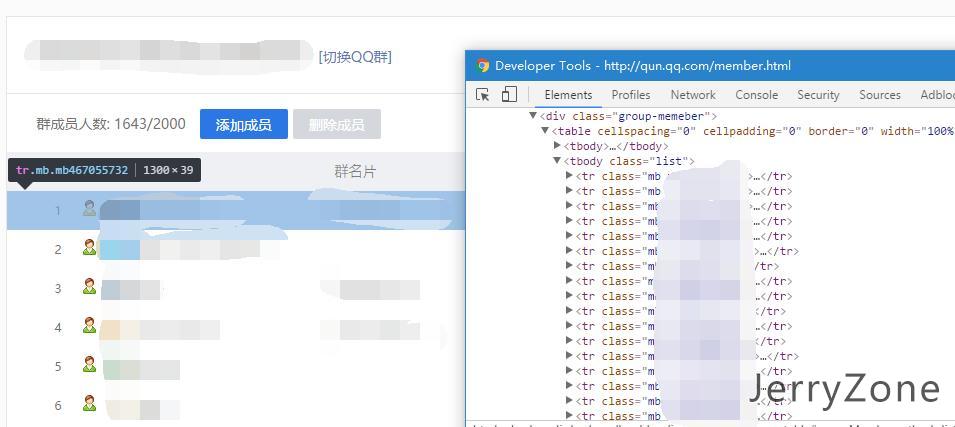
整个页面中我们希望获取到的数据位于.group_member下的一个table中,所以我们需要做的就是把这个table下边的所有行先搞出来:打开控制台选项卡执行一行jQuery代码
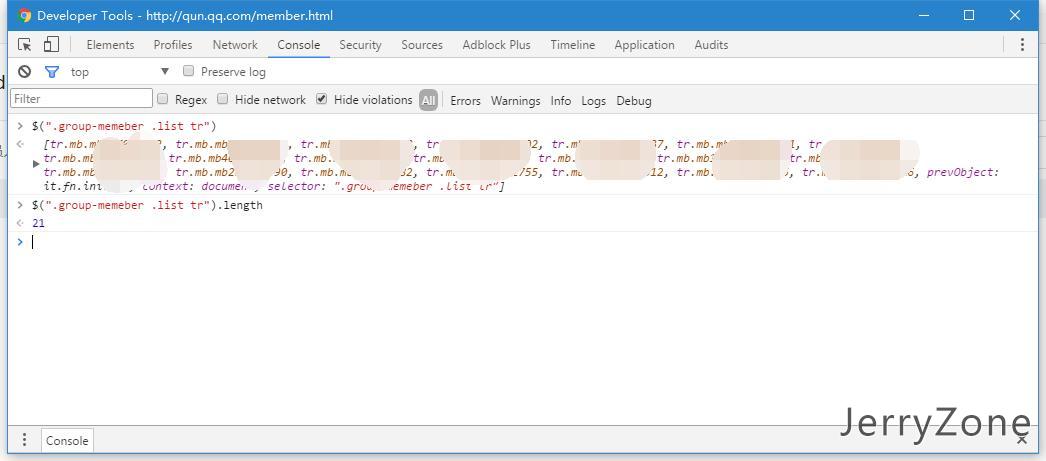
这时候发现本来应该1643个人列表只有21个人,这是因为腾讯为了防止一次加载太多数据页面卡住或者加载全部数据访客只看一小部分导致的流量浪费,把数据的加载改为ajax异步加载了,为了让我们能够一次性把所有数据都导出来,必须先把数据给他全部加载出来。这个网站还好,用的是拖拽到底部自动加载的策略,没有用分页的方式,所以为了加载所有数据到浏览器中,我们就要不停的拖拽到底部。这个操作我们用jQuery来模拟。
intv=setInterval(function(){
//获取现在已经加载多少人了
var loaded=$("#groupMember tr.mb").length;
//获取一共多少人
var total=parseInt($("#groupMemberNum").text())
//输出加载进度
console.info("已加载:",loaded,"总计:",total,parseInt(loaded/total*1000)/10+"%");
//如果已加载和总数相同,停止计时器
if(loaded>=total){
clearInterval(intv);
}else{
//如果不同,说明没有加载完成,继续加载,这里考虑有可能网络延迟导致上一次加载未完成下一次又已经开始导致的报错,自动点确定
if($(".ui-dialog.on").length>0){
$(".ui-dialog.on .icon-close").click();
$("body").scrollTop($(document).height()-$(window).height()*2);
}else{
$("body").scrollTop($(document).height()-$(window).height());
}
}
},500);
当我们获取到所有数据后,就可以再次执行上边获取DOM节点的代码,可以看到1643个人的数据现在已经完全列出来了。

这时候我们就可以用$.each方法来依次枚举每一行的dom元素,从其中取出想要的数据放置在一个全局变量中,等待我们最后的导出。
members=[];
$("#groupMember tr.mb").each(function(i,e){
//这部分要根据页面dom结构来写,不再详细解释
var icon;
var nick=$(e).find(".td-user-nick span").text();
var card=$(e).find(".td-card .group-card").text();
var tag =$(e).find(".td-mark span").text();
var id=$(e).find("td:eq(5)").text();
var sex=$(e).find("td:eq(6)").text();
var qage=$(e).find("td:eq(7)").text();
var joinTime=$(e).find("td:eq(8)").text();
var gradeTag=$(e).find("td:eq(9)").text().split("(")[0];
var grade=$(e).find("td:eq(9)").text().split("(")[1].replace(")","");
var lastPop=$(e).find("td:eq(10)").text();
if($(e).find(".icon-group-manage").length>0) icon="manage"
else if($(e).find(".icon-group-master").length>0) icon="master"
else icon="none"
//入库
members.push({
id:$.trim(id),
nick:$.trim(nick),
sex:$.trim(sex),
qage:$.trim(qage),
group:{job:icon,cardName:$.trim(card),tag:$.trim(tag),joinTime:$.trim(joinTime),lastPop:$.trim(lastPop)},
grade:{tag:$.trim(gradeTag),score:$.trim(grade)}
});
});
当执行完提取代码后,member变量中将保存着所有希望获得的数据:
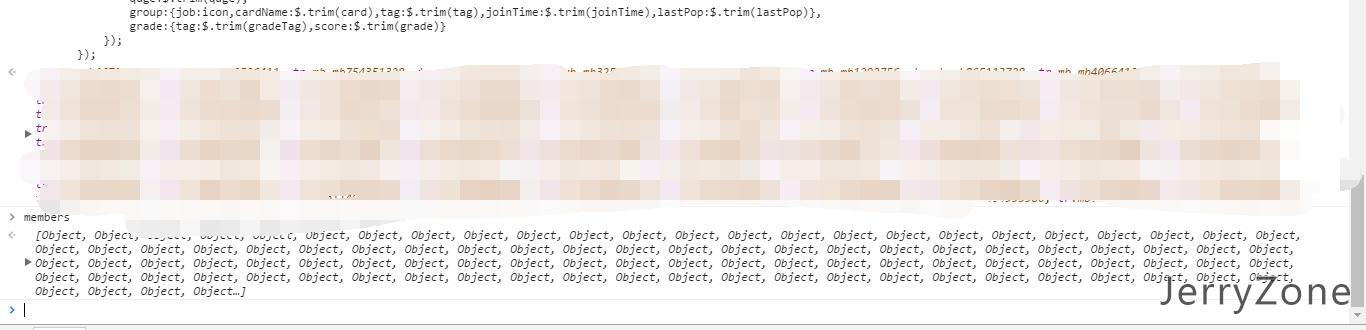
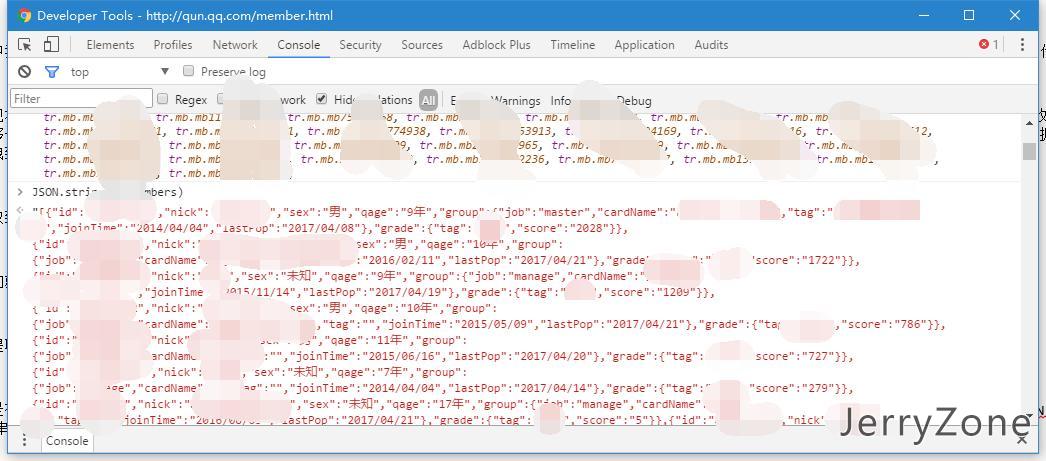
现在还只是存在内存中的数据,最终我们希望得到的数据是保存在文件中的数据,这时候编写一些序列化的代码把js对象转换为指定格式的代码在,这里我直接用的JSON.stringify函数直接转换为JSON字符串,视数据量不同输出时间也不同。至此,我们完整的把整个页面上的数据爬取了下来。
对比基于接口的数据爬取和基于页面的数据爬取
| 基于接口 | 基于页面 | |
| 需要了解页面ajax工作流程 | 是 | 否 |
| 需要模拟登录 | 需要 | 不需要 |
| 直接保存为文件 | 支持 | 不支持 |
| 跨站数据访问 | 支持 | 不支持 |
| 主要知识领域 | 爬虫语言,http | html,js |
| 数据量支持 | 不限 | 数据量过大会导致浏览器缓慢 |
综上所述,基于接口的适合数据量较大但流程较为简单的爬取需求,基于页面适合数据量稍小并且可以由一系列的用户操作完成数据加载的爬取需求。
评论
您需要 先登录 才可以回复.